Elisa Warner, PhD
Austin, TX USA
Projects
Contents
- Bioinformatics
- Neural Nets
- Diffusion Model from Scratch
- [Blog] U-Net: Convolutional Networks for Biomedical Image Segmentation
- [Blog] Understanding OpenAI’s Multimodal CLIP Model
- [Blog] Simplified Intro to Self-Supervised Learning for Computer Vision
- [Blog] Multiple Instance Learning
- [Blog] Backpropagation in PyTorch, Part I
- [Blog] Backpropagation in PyTorch, Part II
- [Blog] ResNets and Residual Connections in Neural Networks
- NLP/Markov Models
- Fake Abstract Generator (Markov Model)
- [Blog] Attention in Deep Learning, Part I
- [Blog] Attention in Deep Learning, Part II
- [Blog] Attention in Deep Learning, Part III
- [Blog] Attention in Deep Learning, Part IV
- [Blog] Attention in Deep Learning, Part V
- [Blog] Attention in Deep Learning, Part VI
- [Blog] I Worked Out the Details to Basic Transformers So You Don’t Have to
- Networks & APIs
- Google Scholar Comparator
- URL Surveillance
- Visualize Crypto Transaction Networks
- Web Traffic Capture
- Command-Line Automated Gmail Script
- Fun
Bioinformatics
Biological Age
See Powerpoint summary from BIOINF 575. See Python Notebook, Python script, and SAS implementations on Github by clicking the title link.
This project began during my internship at Forschungszentrum Jülich. The study is based on the concept of using lab-acquired data to predict a body’s respective health (biological age) with higher accuracy than chronological age. The analysis consisted of comparing two methods: 1) One suggested by Klemera & Doubal and later refined by Levine (see Powerpoint), and 2) a control Multiple Linear Recession algorithm. The study was a replication of a SAS study conducted by Levine on NHANES III data. Later, in a Bioinformatics class, I utilized the same principles with help from Anaconda, pandas, and numpy, to rewrite the program in Python.
My KDM (Klemera-Doubal Method) implementation was employed in a Nature Communications paper entitled, “Age and Life Expectancy Clocks Based on Machine Learning Analysis of Mouse Frailty."
Random Forest+ Privileged Model
See my related blog post on The Bioinformatics Blog.
This work was made for a MICCAI publication entitled,"Predicting Osteoarthritis of the Temporomandibular Joint Using Random Forest with Privileged Information". In this work, I present a python implementation of a random forest method that can accommodate a special type of information, called "privileged information" which is available only in training and not in testing, and is designed to provide additional information for the model to learn with. An example of privileged information in a medical setting could be MRI scans to assist in drawing conclusions about formations in CT scans. The reason the MRI scans would be privileged would be because there are too few examples of them to be used in testing. For more information, consult my journal publication or blog post (linked above).
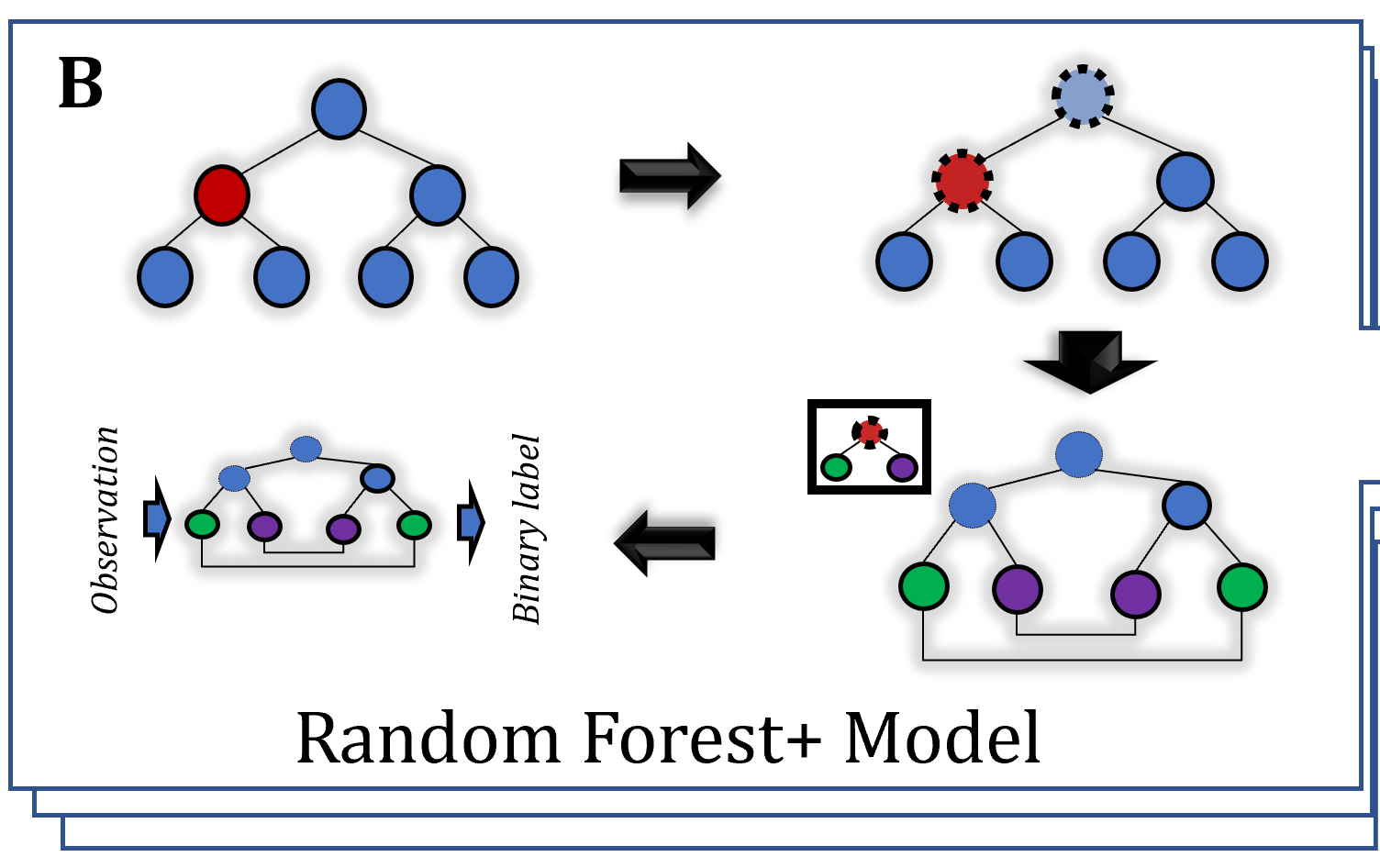
Single Cell Patient Comparison
The foundational question of this project attempts to solve is the following: if you had a collection of single-cell data of different patients for a given cell type, can you find a way to compare patients? What we aimed to do was compare individuals based on the covariances of their genes. The notebook contains various metrics that were taken on the covariances of genes and then visualized in a grid to compare patients via the distances between gene covariances. The code is available for people to use, but it’s recommended that you pick data where n >> p (either lower the dimensionality of your gene features to less than the number of samples of cells per patient). The code presents several ways to compare patient-level single-cell data if the user has adequate data.
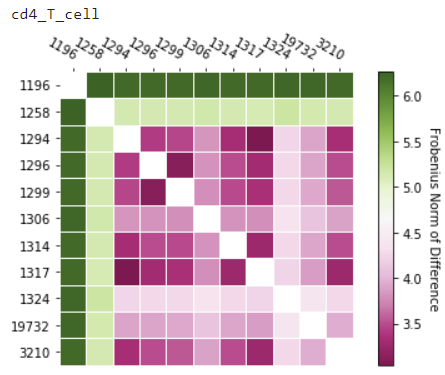
H&E Image Toolkit
This repository uses openslide to help users easily extract image tiles from large images of H&E microscope slides (usually at 10x-20x). The user simply selects an appropriate window size and slide length, and tiles will be saved in a desired output folder. Tiles with a user-defined percentage of whitespace or greater will also be removed.
The image below is an example of an H&E Image for reference. Attribution: KajsaMollersen, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
Neural Nets
Diffusion Model from Scratch
See my related article describing diffusion models in detail on The Bioinformatics Blog here.
In this project, I use a diffusion model to generate 32x32 images of cat faces. The details of the diffusion model and how they work, complete with equations and a description of the algorithm and proof are given in my blog link above.

NLP/Markov Models
Fake Abstract Generator
This code was part of a pet project I made to play with Markov models. The code trains a model using 5 years’ worth of CVPR (Computer Vision and Pattern Recognition) abstracts, then outputs an abstract according to a pre-specified word count by the user. The user also has the choice to change the order of the model (a first-order model will make less sense but be more “random” than a tenth order model, for example). It also (once again) demonstrates use of Flask (the user runs the code to build a server from which the landing page will show). Flask is a python package that allows the programmer to create a front-end service through a local server.


Networks & APIs
Google Scholar Comparator
This was a final project for a class that included OAuth/API use and web scraping. The program features a simple browser UI on the local server, where a user can input several search topics on Google Scholar. The output gives a graph of the distribution of citations for papers related to each respective topic (based on the first 50 pages of Google Scholar hits). The ensuing tables display a parsed view of the top five hits for each entered topic. For more information, click the link on the title.
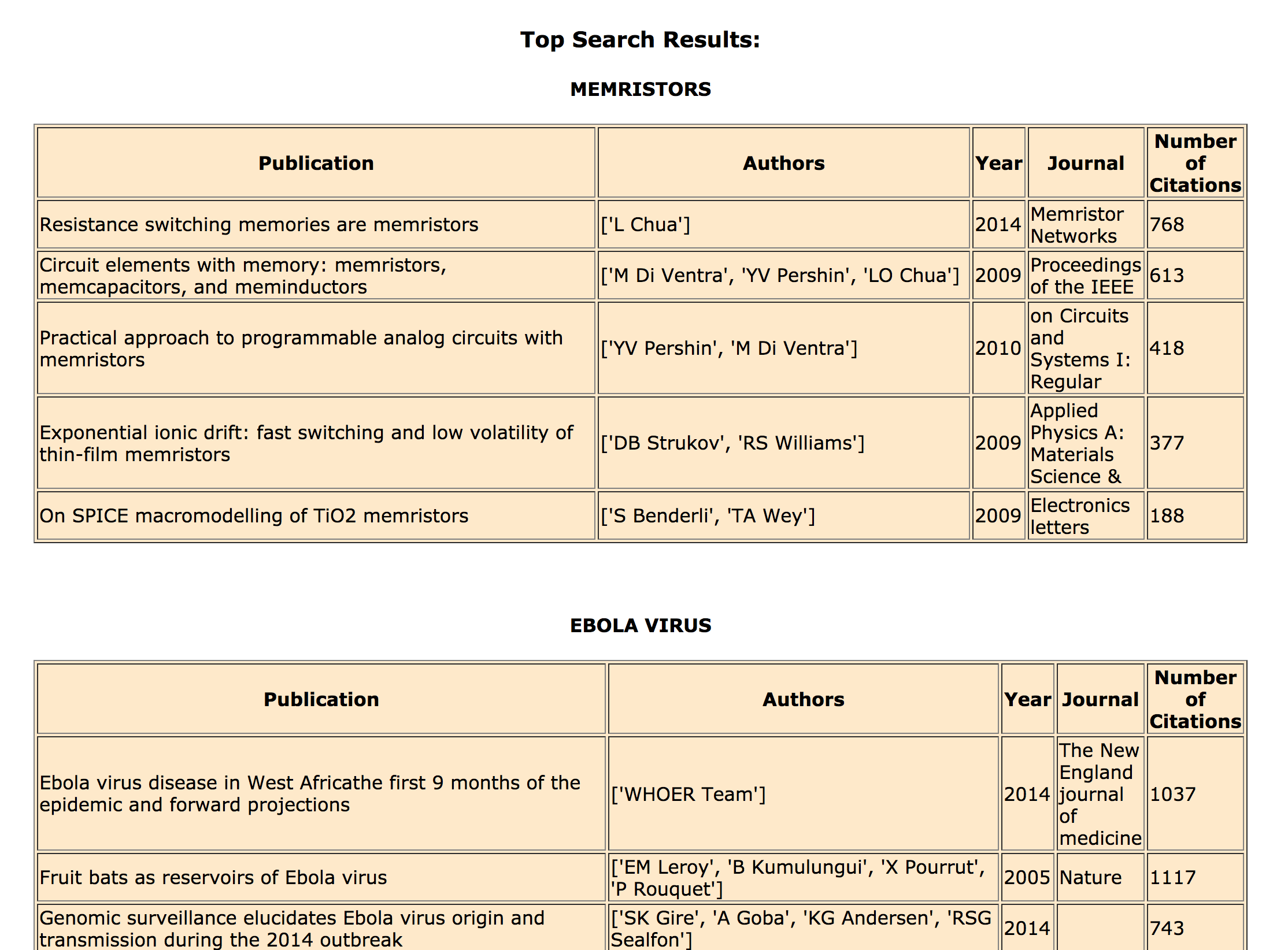
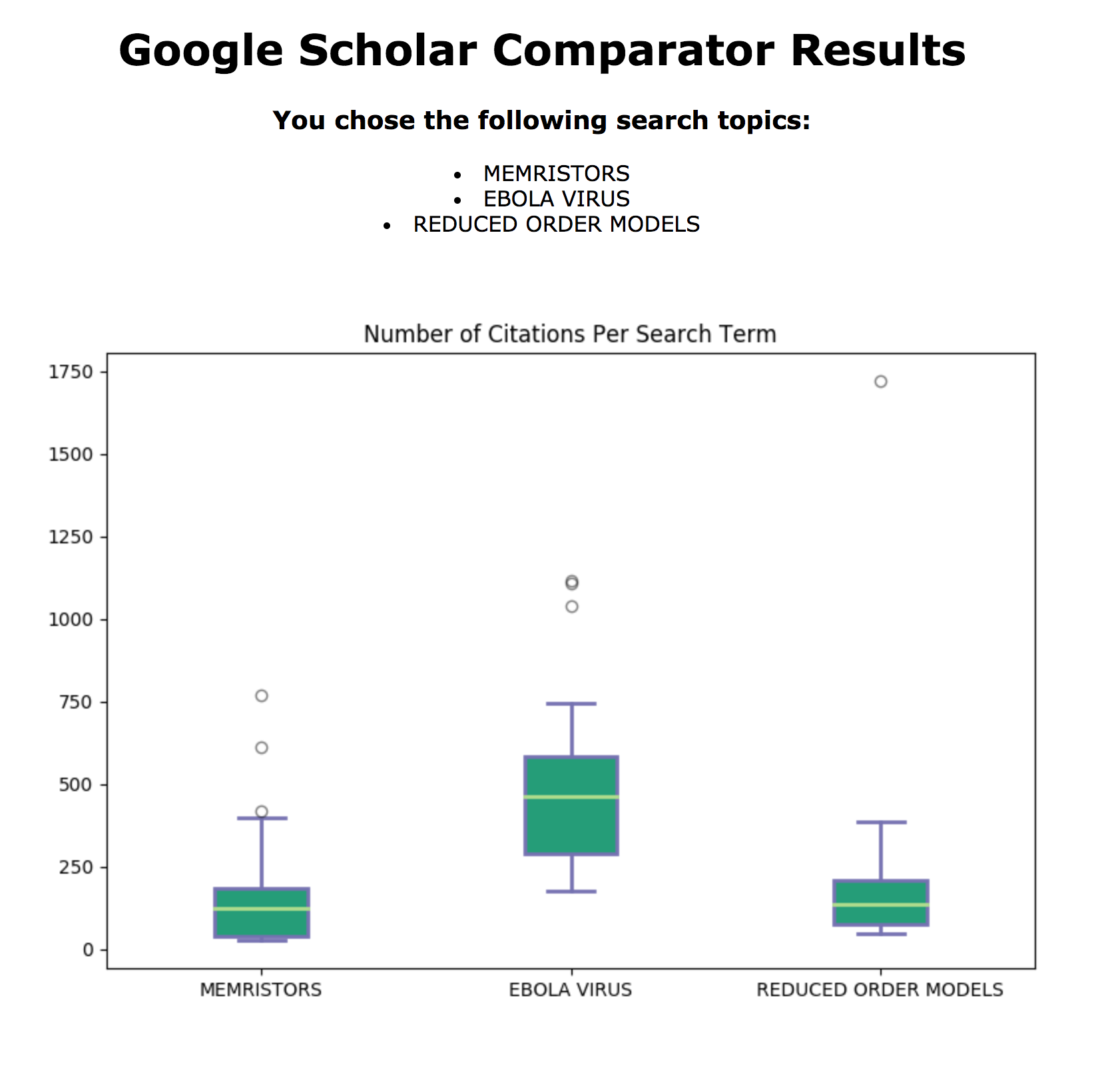
URL Surveillance
WHOIS lookup using an API can be found here
This code was developed with the intention of analyzing a list of thousands of fraudulent websites, and to be able to run this code regularly every few weeks to understand which websites were still up, if server hosts were changing, or if trends in the fraudulent websites were shifting. The code primarily assesses two things: 1) conducts an nslookup on the fraudulent website and saves the fields in a tabular format, and 2) Uses an API to assess the IP addresses grabbed from step 1 to understand the location, org, and autonomous system of the host servers. In the WHOIS code (also linked), registrations for domain names, included names of the registrar and contact information of the individuals (if given) are searched and listed.
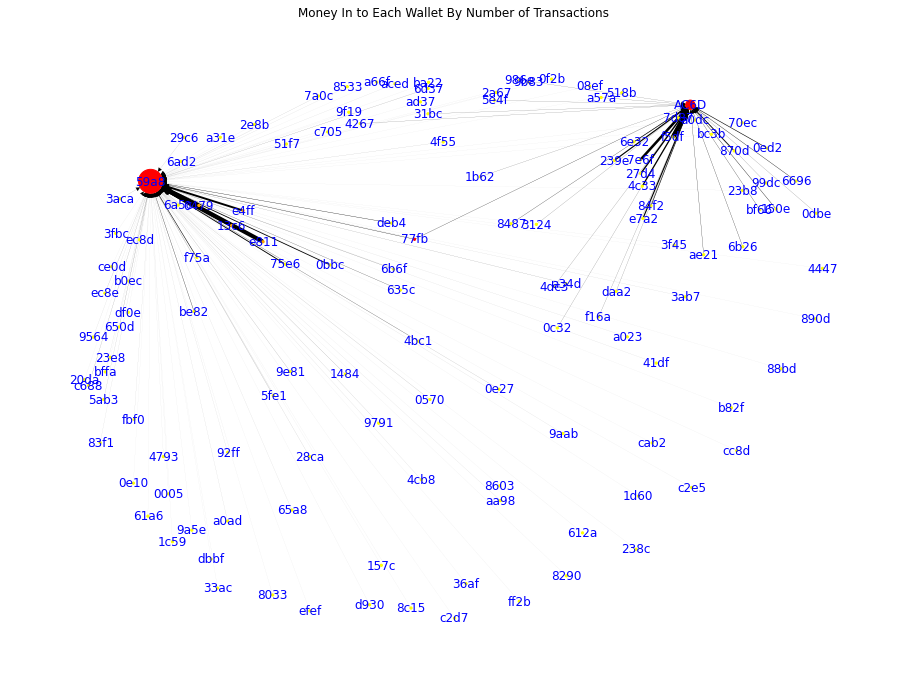
Visualize Crypto Transaction Networks
This analysis uses etherscan.io's API to automatically cache and download up to 5 levels of transactions from a list of target wallets and draw networks of biggest funders and biggest beneficiaries of financial transactions to and from the desired list of wallets.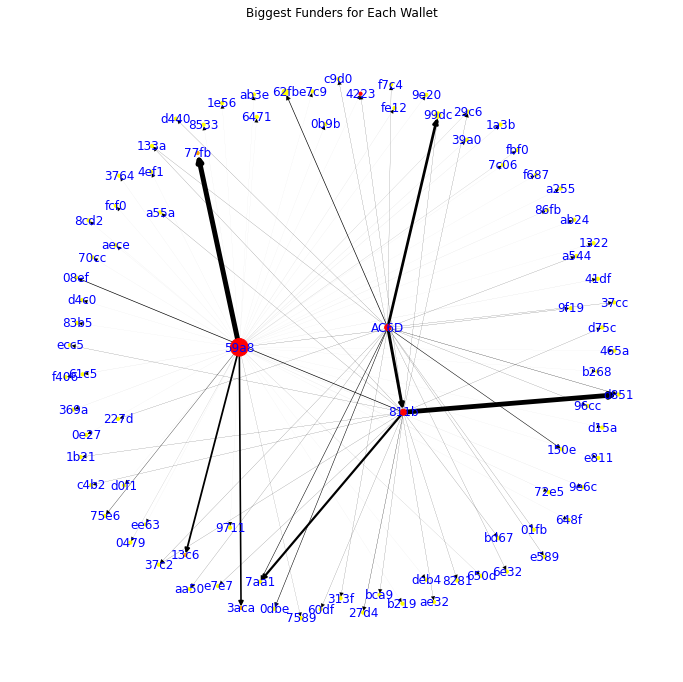
Web Traffic Capture
This script was an experiment based on what I learned from the Google IT Support Professional Certificate on Coursera. After learning about tcpdump, I created a script which leverages this package to track all incoming DNS responses. This means that all websites visited in both the foreground and background are tracked and a simple frequency analysis is made. This enables users to track, for a given Internet session, what websites are being visited directly and implicitly, and use for process monitoring, ad blocking, and bot surveillance, among others.
Command-Line Automated Gmail Script
This was written in the same day as the above project. It was simply written out of a desire to automate my lab meeting messaging. This Gmail Script allows you to create templates of commonly-written emails that require a few blanks (like names) to be filled in. Then, you can specify in one command line which template to use and what the blanked values should be, and then the email is sent immediately.
Fun
Warner Pong
This is a pet project still under construction that I made to see how pygame works and also to recreate my Dad’s old Turbo C recreation of the original Pong game. He of course made his version educational, which I will try to do when I have time. In the meantime, enjoy the game for all its simplicity!
Note the image below is a demonstration of the gameplay. The paddle on the left (in red) is the computer movement (no, I did not use reinforcement learning). The paddle on the right (in blue) is me.